لقد تطورت تقنية تحويل النص إلى كلام بشكل كبير في السنوات الأخيرة، لكن معظم الأنظمة لا تزال تواجه قيودًا عند استنساخ الأصوات دون بيانات تدريب مكثفة. يمثل نظام MiniMax-Speech خطوة مهمة إلى الأمام لأنه يوفر استنساخًا صوتيًا حقيقيًا بدون لقطة صوتية لا يتطلب صوتًا مرجعيًا مكتوبًا.
الابتكارات التي تميّز MiniMax-Speech
هناك ابتكاران رئيسيان يجعلان MiniMax-Speech متميزًا عن أنظمة تحويل النص إلى كلام الحالية:
برنامج ترميز مكبر الصوت القابل للتعلم الذي يلتقط خصائص الصوت من الصوت غير المكتوب، مما يتيح استنساخاً صوتياً حقيقياً بدون أي لقطة
بنية Flow-VAE التي تعزز جودة الصوت وتشابه المتحدث من خلال تحسين تمثيل المعلومات
على عكس النماذج الأخرى التي تدّعي قدرات "اللقطة الصفرية" ولكنها تتطلب في الواقع أمثلة نصية صوتية مقترنة(وهي مشكلة شائعة في المقاربات السابقة)، يمكن لبرنامج MiniMax-Speech توليد كلام عالي الجودة بصوت مستهدف باستخدام عينة صوتية غير مكتوبة فقط .
الاستنساخ الصفرى الحقيقي للصوت
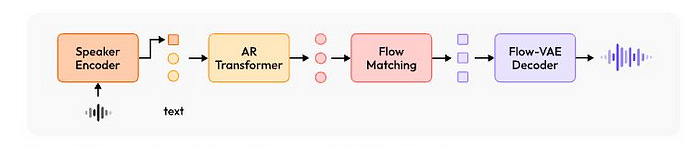
يستخدم برنامج MiniMax-Speech بنية محول انحداري تلقائي مشابه لتلك المستخدمة في النماذج اللغوية الكبيرة. ويتمثل الاختلاف الرئيسي في مشفر مكبر الصوت الخاص به، والذي يستخرج الجرس والنمط الصوتي من الصوت المرجعي دون الحاجة إلى أي نسخ صوتي.
يتم تدريب مُشفّر المتكلم بشكل مشترك مع النموذج الانحداري التلقائي، على عكس الأنظمة التي تستخدم نماذج التحقق من المتكلمين المدربة مسبقًا. يسمح هذا التدريب المشترك للمشفّر بالتقاط الخصائص المحددة اللازمة لتوليف الكلام عالي الجودة بشكل أفضل.
يوفر هذا النهج العديد من المزايا:
لا حاجة للنسخ الصوتي المرجعي
قدراتتوليف متعدد اللغات
نغمة أكثر طبيعية حيث أن النموذج غير مقيد بأمثلة فورية
استنساخ صوتي مرن عبر 32 لغة
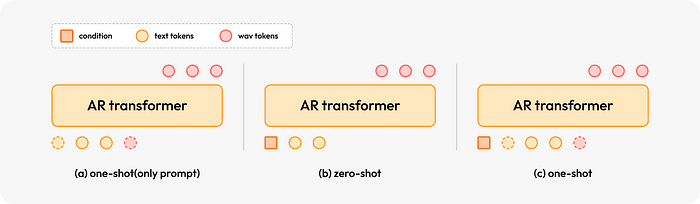
بينما يدعم MiniMax-Speech كلاً من الاستنساخ الصفرى والاستنساخ بلقطة واحدة، فإن إمكانياته التي لا تحتاج إلى لقطة واحدة هي ما يميزه حقًا عن الأنظمة الأخرى مثل VALL-E و CosyVoice 2 و Seed-TTS، والتي تتطلب عينات نصية صوتية مقترنة لتكييف مكبر الصوت.
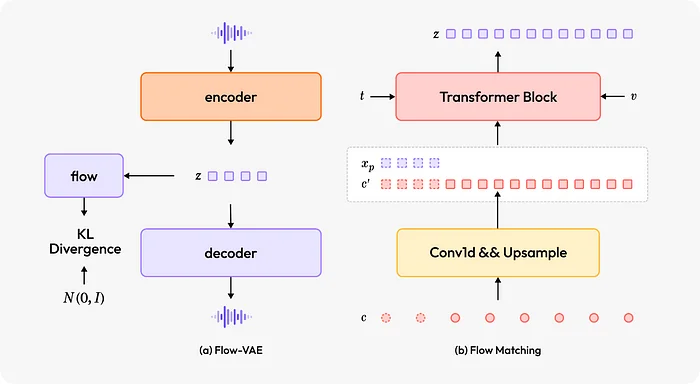
تحسين جودة الصوت مع Flow-VAE
الابتكار الرئيسي الثاني في نظام MiniMax-Speech هو بنية Flow-VAE، التي تعمل على تحسين جودة الصوت بشكل كبير.