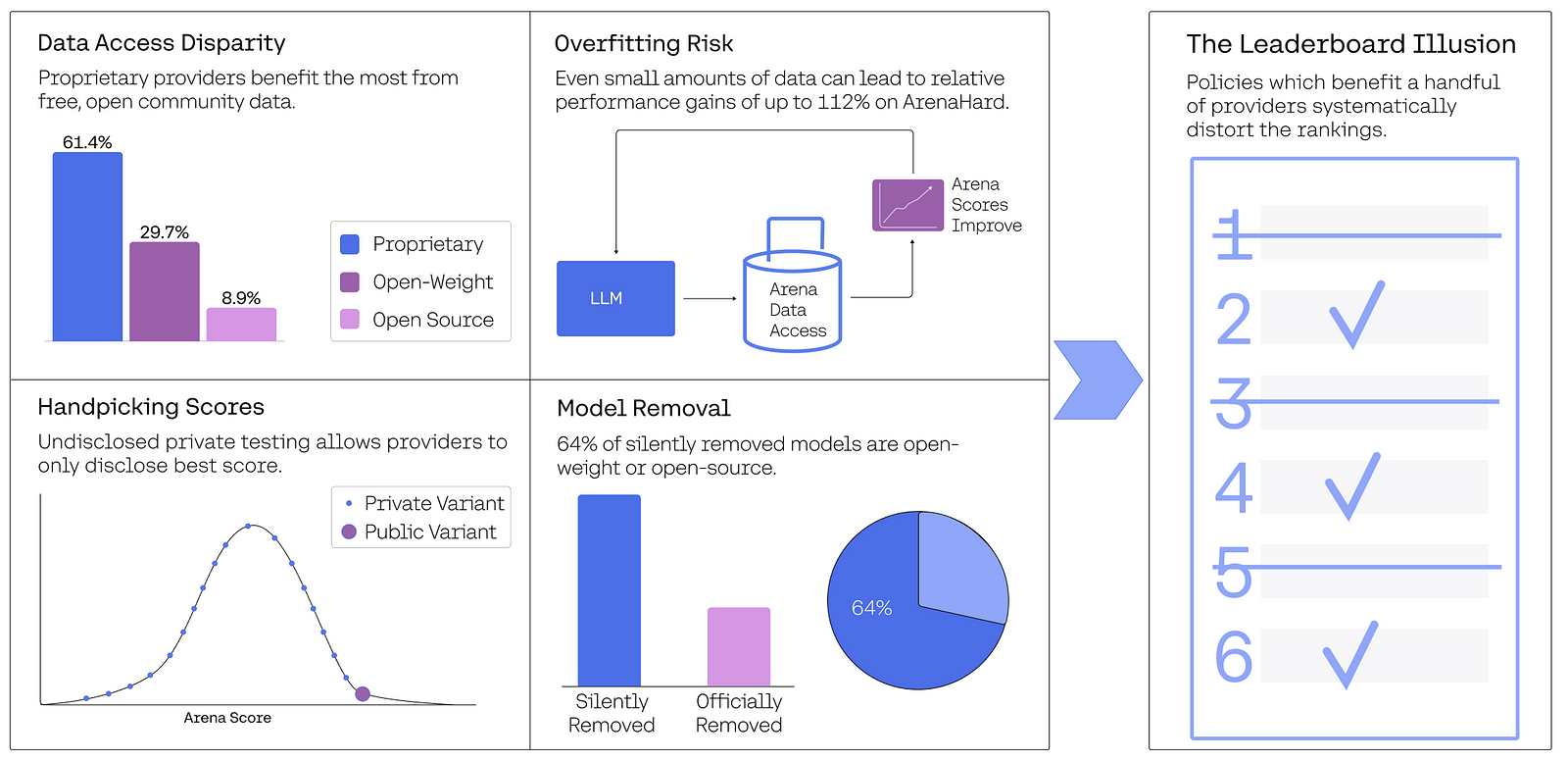
من الواضح أن المعايير تلعب دوراً كبيراً في أبحاث الذكاء الاصطناعي وتوجيه التقدم وقرارات الاستثمار. تُعد Chatbot Arena هي لوحة المتصدرين لمقارنة النماذج اللغوية الكبيرة، ولكن يكشف بحث جديد عن بعض المشكلات المنهجية التي خلقت مجالاً غير متكافئ، مما قد يقوض النزاهة العلمية والتقييم الموثوق للنماذج.
كيف تعمل Chatbot Arena ولماذا هي مهمة
أصبحت Chatbot Arena المعيار الأساسي لتقييم نماذج الذكاء الاصطناعي التوليدي. يقوم المستخدمون بإرسال المطالبات والحكم على أي من النموذجين المجهولين يؤدي بشكل أفضل. وقد اكتسب هذا التقييم البشري في الحلقة أهمية كبيرة لأنه يجسد الاستخدام الواقعي بشكل أفضل من المعايير الأكاديمية الثابتة.
أجرى الباحثون مراجعة منهجية لـ Chatbot Arena، حيث قاموا بتحليل بيانات 2 مليون معركة تغطي 243 نموذجاً عبر 42 مزوداً في الفترة من يناير 2024 إلى أبريل 2025. تكشف النتائج التي توصلوا إليها عن كيفية تشويه بعض الممارسات لتصنيفات لوحة المتصدرين.
تستخدم الساحة نموذج Bradley-Terry (BT) لتصنيف المشاركين بناءً على مقارنات ثنائية. على عكس الحسابات البسيطة لمعدل الفوز، يأخذ BT في الحسبان قوة الخصم ويوفر تصنيفات قائمة على أسس إحصائية. ومع ذلك، يعتمد هذا النهج على افتراضات رئيسية: أخذ عينات غير متحيزة، وانتقالية التصنيفات (إذا تغلب (أ) على (ب) و(ب) على (ج)، فيجب أن يتغلب (أ) على (ج))، ورسم بياني للمقارنة متصل بشكل كافٍ.
ميزة الاختبار الخاص
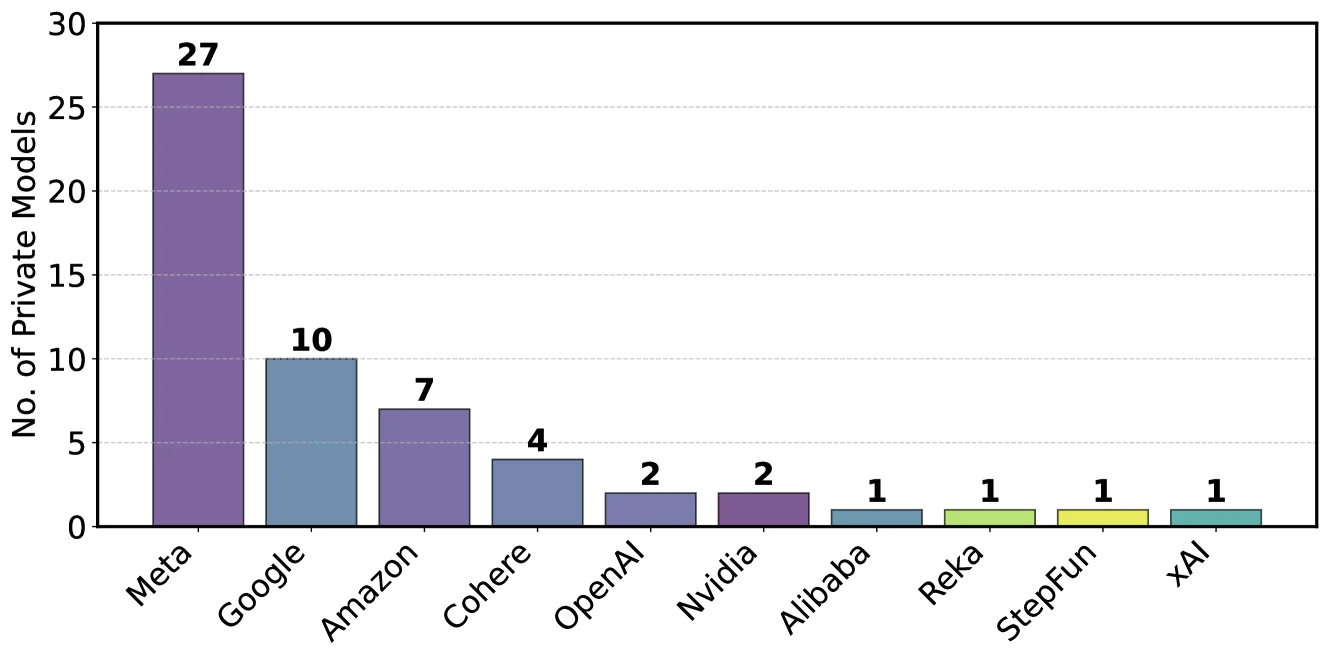
إحدى أكثر النتائج المثيرة للقلق هي سياسة غير معلنة تسمح لبعض مقدمي الخدمات باختبار نماذج متعددة بشكل خاص قبل الإصدار العام، ثم إرسال النموذج الأفضل أداءً بشكل انتقائي فقط إلى لوحة المتصدرين.

اكتشف الباحثون أن شركة Meta اختبرت 27 نموذجًا خاصًا قبل إصدار Llama-4، بينما اختبرت Google 10 نماذج مختلفة. في المقابل، لم يكن لدى الشركات الأصغر مثل ريكا سوى متغير خاص واحد نشط، ولم تختبر المختبرات الأكاديمية أي نماذج خاصة خلال هذه الفترة.
تنتهك استراتيجية التقديم "الأفضل من N" هذه استراتيجية التقديم "الأفضل من N" افتراض أخذ العينات غير المتحيز لنموذج BT. ومن خلال محاكاة هذا التأثير، أظهر الباحثون أن اختبار 10 متغيرات فقط ينتج عنه زيادة بمقدار 100 نقطة تقريباً في الحد الأقصى للدرجة المحددة.
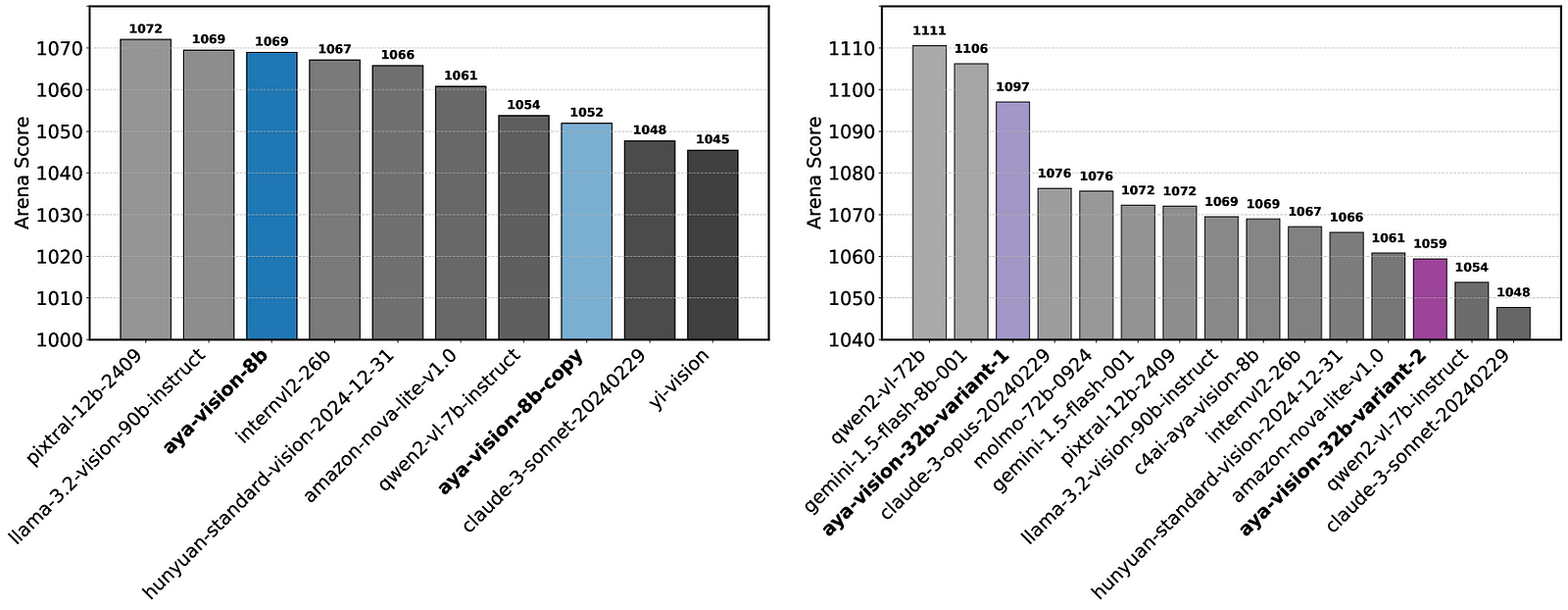
قام الباحثون بالتحقق من صحة نتائج المحاكاة هذه من خلال تجارب العالم الحقيقي على Chatbot Arena. وقد قدموا نقطتي اختبار متطابقتين من Aya-Vision-8B ووجدوا أنهما حققتا نتائج مختلفة (1052 مقابل 1069)، مع وضع أربعة نماذج بين هذين المتغيرين المتطابقين على لوحة المتصدرين. عند اختبار متغيرين مختلفين من Aya-Vision-32B، لاحظوا فروقاً أكبر في الدرجات (1059 مقابل 1097)، مع وضع تسعة نماذج بينهما.
تفاوتات شديدة في الوصول إلى البيانات
يكشف البحث عن وجود تفاوتات كبيرة في الوصول إلى البيانات من معارك Chatbot Arena، والتي تنبع من ثلاثة عوامل رئيسية: