
يعد توليد مشاهد تفاعلية ثلاثية الأبعاد من النص أمرًا ضروريًا للألعاب والواقع الافتراضي وتطبيقات الذكاء الاصطناعي المجسدة. على عكس توليد المشهد الأحادي الهندسة، يتطلب توليف المشهد التفاعلي ترتيب الأجسام في تخطيطات واقعية تحافظ على التفاعلات الطبيعية والأدوار الوظيفية والمبادئ الفيزيائية. على سبيل المثال، يجب أن تكون الكراسي في مواجهة الطاولات من أجل جلوس مناسب، بينما تحتاج العناصر الصغيرة إلى وضع مناسب داخل الخزانات أو على الرفوف دون اختراق.
تواجه الأساليب الحالية قيودًا كبيرة. تعتمد الأساليب القائمة على التعلم على مجموعات بيانات داخلية صغيرة الحجم مثل 3D-FRONT، مما يحد من تنوع المشهد وتعقيد التخطيط. وفي حين يمكن لنماذج اللغة الكبيرة (LLMs) الاستفادة من المعرفة بالمجال النصي، إلا أنها تفتقر إلى الإدراك البصري، مما يؤدي إلى مواضع غير طبيعية للأشياء لا تحترم العلاقات المكانية المنطقية.

يعالجScenethesis هذه التحديات من خلال رؤية رئيسية: يمكن للإدراك البصري أن يسد الفجوة المكانية التي تفتقر إليها أنظمة LLMs. يدمج هذا الإطار العميل الخالي من التدريب بين تخطيط المشهد القائم على LLM مع تنقيح التخطيط الموجه بالرؤية، مما يخلق مشاهد تفاعلية ثلاثية الأبعاد متنوعة وواقعية ومعقولة فيزيائيًا.
مشكلة مناهج توليد المشاهد الحالية
تتطلّب أساليب توليد المشاهد التفاعلية التقليدية مثل التصميم اليدوي عمالة كثيفة وغير قابلة للتطوير، بينما تنتج الأساليب الإجرائية مشاهد مبسطة للغاية تفشل في التقاط العلاقات المكانية الواقعية.
تتيح مناهج التعلم العميق الحديثة التي تستخدم النماذج الانحدارية التلقائية وأساليب الانتشار توليد تخطيط ثلاثي الأبعاد من البداية إلى النهاية ولكنها تعتمد على مجموعات بيانات مُعلَّلة بالأشياء مثل 3D-FRONT. مجموعات البيانات هذه صغيرة الحجم وتقتصر على البيئات الداخلية وغالباً ما تحتوي على تصادمات. فهي تصمم في المقام الأول تخطيطات الأثاث الكبيرة مع إهمال الأجسام الصغيرة وتفاعلاتها الوظيفية.

في حين أن طريقة LLMs توسع من تنوع المشهد من خلال الاستفادة من المعرفة المنطقية من النص، فإن افتقارها إلى الإدراك البصري يمنع إعادة إنتاج دقيق للعلاقات المكانية في العالم الحقيقي. كما هو موضح في الشكل 2، غالبًا ما تخطئ المشاهد التي يتم إنشاؤها بواسطة LLM في توجيه الأجسام (الكراسي في مواجهة الخزائن بدلاً من الطاولات) وتضعها في غير مكانها (الخزائن في مواجهة النوافذ). وتقتصر الأجسام الصغيرة على مواقع محددة مسبقًا (فقط فوق الأثاث وليس بداخله). يؤدي هذا الافتقار إلى الواقعية إلى تعطيل وظائف الكائنات والتماسك المكاني، مما يجعل المشاهد غير عملية لسهولة الاستخدام في العالم الحقيقي.
حاولتالمقاربات المنظمة بشكل هرمي معالجة بعض هذه المشاكل، ولكن يبقى التحدي الأساسي المتمثل في الجمع بين فهم اللغة والوعي المكاني.
المشهدية: نظرة عامة على إطار عمل متعدد العوامل
إن Scenethesis هو إطار عمل وكيلي خالٍ من التدريب يدمج تخطيط المشهد القائم على LLM مع التنقيح المكاني الموجه بالرؤية. ويستفيد هذا النهج من نماذج أساس الرؤية التي تشفر المعلومات المكانية المدمجة وتولد توزيعات مشهدية متماسكة تعكس تخطيطات العالم الحقيقي.
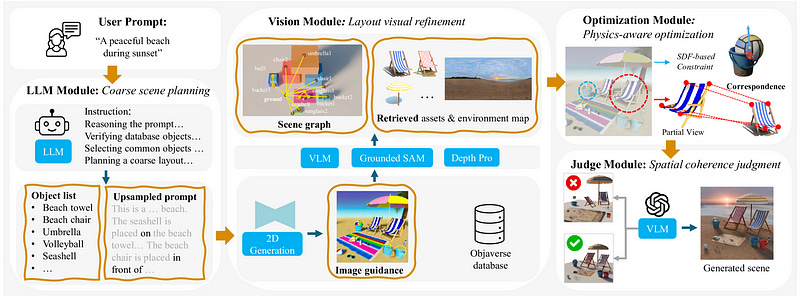
كما هو موضح في الشكل 3، يتكون الإطار من أربع مراحل رئيسية: