
Reasoning models are delivering impressive performance on challenging tasks, but they have a costly flaw: they generate excessive tokens that don’t improve accuracy. This problem, known as overthinking, wastes computational resources and increases inference costs unnecessarily.
A new paper out of UCSB aims to address this problem. The researchers introduce three key contributions to solve this issue
Developing measures of problem-level difficulty that demonstrate the relationship between difficulty and optimal token spend
Creating the dumb500 dataset to evaluate overthinking on extremely simple problems, and
Introducing ThoughtTerminator, a training-free decoding technique that significantly improves reasoning model calibration.
This research builds on prior work exploring efficient reasoning in large language models, but uniquely focuses on difficulty-calibrated token budgeting to maximize efficiency without sacrificing performance.
How Difficulty Relates to Token Spend in Reasoning
The researchers formalize question difficulty as the inaccuracy rate of models when answering a specific question. This operational definition captures how challenging a problem is for current AI systems rather than relying on human judgment.
Their analysis reveals a clear relationship between question-level difficulty and the average token spend across multiple datasets: MATH500, GPQA, and ZebraLogic. As questions get harder, models naturally spend more tokens attempting to solve them, but they do so inconsistently.
This finding relates to other research on reasoning efficiency, such as thoughts being all over the place in underthinking models, which explores the inverse problem of insufficient token allocation.
Measuring Overthinking Quantitatively
The researchers define two key metrics to measure overthinking:
Global overthinking score (Og): The mean difference between a model’s average token spend and the global minimum spend observed across all models for each question.
Local envelope overthinking score (Oenv): The mean difference between the maximum and minimum token spend within a single model for each question.
These metrics reveal that reasoning models (QwQ and DeepSeek-R1 variants) exhibit significantly higher overthinking tendencies than non-reasoning models, with some wasting over 10,000 tokens per question on average.
The dumb500 Dataset: Testing Models on Simple Questions
While overthinking on hard problems is expected, a crucial gap existed in evaluating how models handle extremely simple questions. The researchers created dumb500, a dataset of 500 deliberately simple questions that humans can answer with minimal cognitive effort.
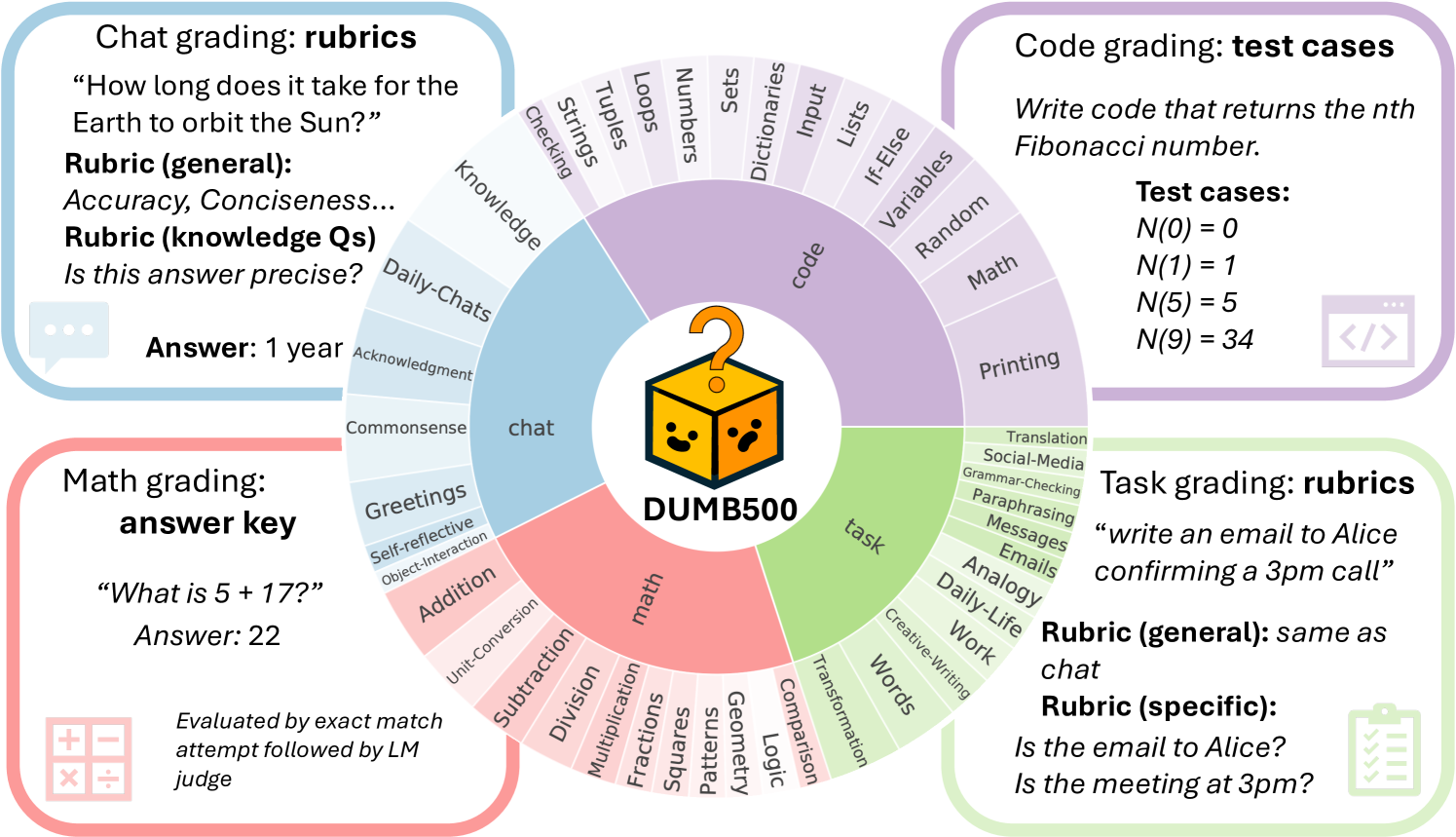
Figure 2: dumb500 dataset composition and grading method. The dataset contains four subsets (chat, code, task & math), each evaluated with domain-specific methods. Image from the paper.
Dumb500 spans four domains:
Mathematics: Basic arithmetic, comparisons, and simple logical reasoning
Conversational Interaction: Casual dialogue, self-reflection, common knowledge
Programming & Computing: Fundamental coding concepts and data structures
Task Execution: Simple natural language processing tasks
The goal is to evaluate models on two dimensions: accuracy (can they answer correctly?) and efficiency (can they do so concisely?).
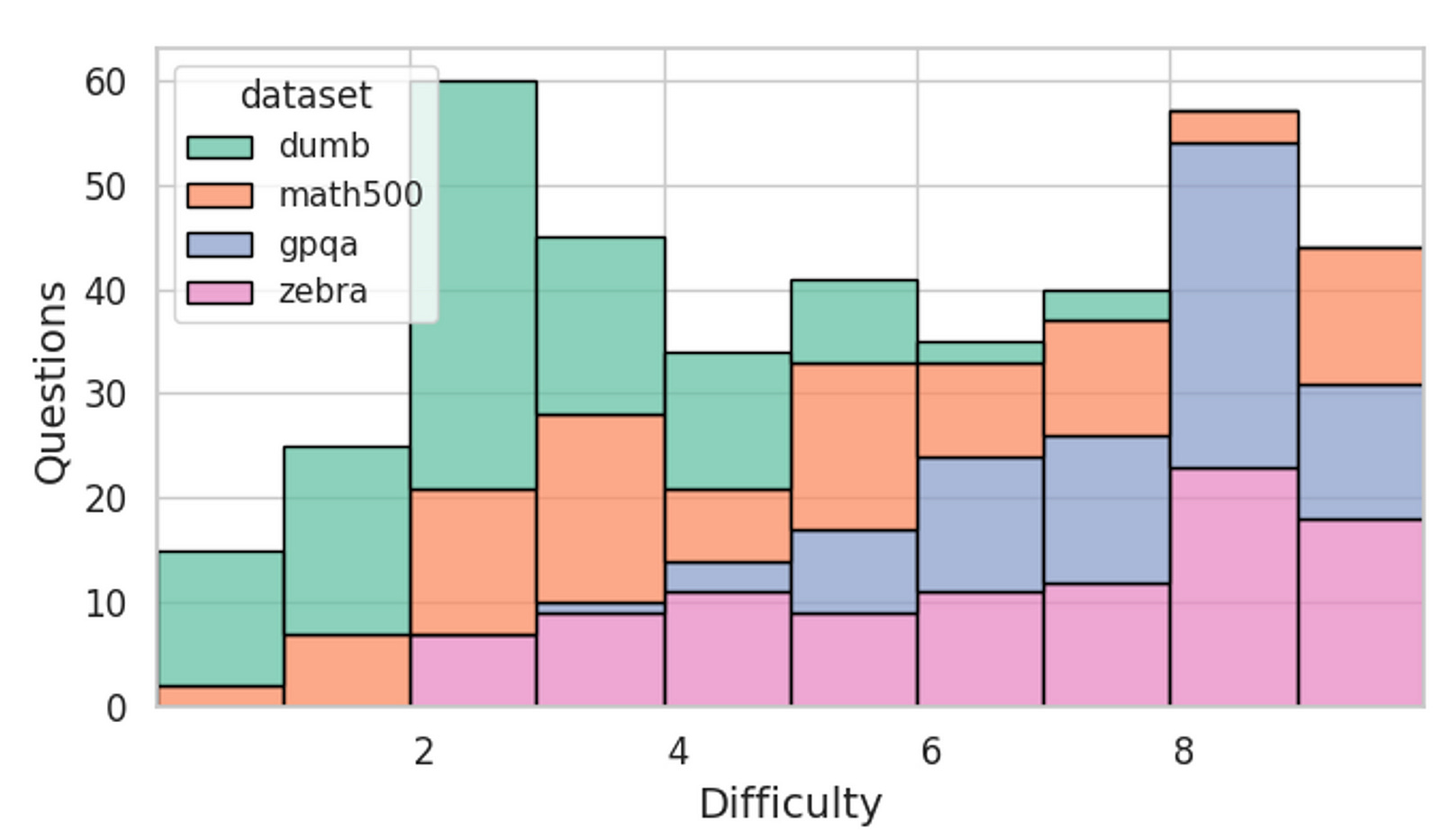
Figure 3: Total difficulty distribution of the four datasets evaluated in this work. By including dumb500 in the analysis, the researchers can characterize overthinking behavior more consistently across the difficulty spectrum.
Specialized Evaluation Methods for Different Question Types
Each domain in dumb500 requires different evaluation approaches:
Math questions: Evaluated using simple accuracy methods, identical to MATH500, GPQA, and ZebraLogic
Code questions: Include test cases for the program described in the prompt, with a Python-based autograder
Chat questions: Evaluated on requirements like appropriateness and conciseness using a GPT-4o judge
Task questions: Assessed based on generic requirements and question-specific criteria for following instructions
This comprehensive evaluation framework allows for consistent assessment across diverse question types.
Analyzing Model Performance from Easy to Hard Questions
When testing the same models on dumb500, the researchers found that token spend has no positive correlation with accuracy on simple math questions — and sometimes even shows a negative relationship for other domains.
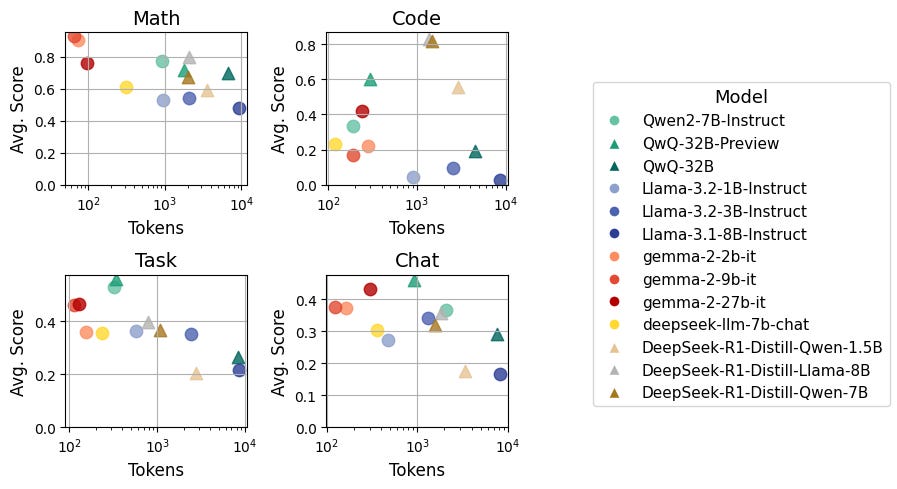
Figure 4: Relationship between average token spend and average score for the evaluated models on each subset of dumb500.
This confirms that models are poorly calibrated on easy problems, often spending unnecessary tokens without improving performance. This finding aligns with research on thinking in tokens in language modeling, which examines how models allocate computational resources during inference.